Das Szenario einer Mitarbeiterbefragung an mehreren Standorten
Um eine Mitarbeiterbefragung auswerten zu können, braucht es möglichst viele Daten. Im Rahmen von Mitarbeiterbefragungen ist deshalb immer das Ziel, möglichst viele Mitarbeiter zu erreichen und somit eine hohe Rücklaufquote zu gewährleisten. Je mehr Mitarbeiter sich an einer Befragung beteiligen, desto aussagekräftiger sind naturgemäß die Ergebnisse. Nehmen wir an, ein Unternehmen mit 220 Mitarbeitern und 15 bundesweiten Niederlassungen habe sich entschieden, eine Befragung durchzuführen. Die Mitarbeiterzahlen in den Niederlassungen variieren von 5 bis zu 20 Mitarbeitern. Im Zuge der Analysen wurde ein Motivationsindex aus verschiedenen einzelnen Fragen konstruiert, dessen Ergebnisse für die Geschäftsführung von besonderem Interesse sind.
In der Vergangenheit zeigte sich, dass die Umsätze in einigen Niederlassungen deutlich stiegen, stagnierten oder aber gar fielen, obwohl sich die wirtschaftlichen Voraussetzungen zwischen den Standorten nicht veränderten. Man will also mit statistischen Methoden prüfen, ob es Unterschiede bezüglich des Motivationsindexes (MI) zwischen den Niederlassungen gibt, da man davon ausgeht, dass diese direkt auf Umsätze und Gewinne wirken.
Eine erste statistische Idee zum Auswerten der Mitarbeiterbefragung – doch worin unterscheiden sich die Standorte wirklich?
Der statistisch geschulte Leser kann nun auf die erste Idee kommen, die Unterschiede zwischen den Niederlassungen mittels varianzanalytischer Verfahren zu prüfen, was nachvollziehbar und richtig ist, so denn die Voraussetzungen des Verfahrens erfüllt sind. Im ersten Schritt kann es jedoch sinnvoll sein, festzustellen, wieviel Variabilität überhaupt auf die Niederlassungen zurückzuführen ist.
Die Unterschiedlichkeit der Variable „Motivationsindex“ (MI) wird statistisch durch die Varianz beschrieben. Sie ist ein Maß für die Variabilität des MI. Wollen wir nun wissen, welcher Anteil an Varianz des MI auf die verschiedenen Niederlassungen zurückzuführen ist und nicht auf andere Variablen, so kann der Einsatz eines Random-Effects Modells als Spezialfall eines Mehrebenenmodells hilfreich sein. Dabei interessieren nicht die konkreten Unterschiede zwischen den Niederlassungen A und B, A und C, B und C usw., sondern, welcher Anteil der Gesamtvarianz des MI auf die Niederlassungen zurückzuführen ist.
Das Random-Effects Modell
Um diese Frage zu beantworten, stellen wir ein Random-Effects Modell auf, bei dem in unserem Beispiel keine weiteren Einflussgrößen berücksichtigt werden, man bezeichnet dies auch als Nullmodell. Dieses hat die folgende Form und dient der Untersuchung der Varianzkomponenten. Die erste Komponente bezieht sich auf die Niederlassungen, während die zweite Komponente ungeklärte Varianz zusammenfasst und als Fehlervarianz bezeichnet wird.
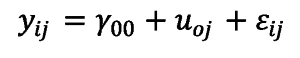
mit:
yij = MI des i-ten Mitarbeiters der j-ten Niederlassung
γ00 = MI-Gesamtmittelwert aller Niederlassungen
uoj = Random Effect der j-ten Niederlassung
εij = Fehlerkomponente (MI-Abweichung des Mitarbeiters von seinem Niederlassungsmittelwert)
Der zufällige Effekt (random effect) beschreibt in diesem Modell die Abweichung des Mittelwertes einer Niederlassung vom Gesamtmittel aller Niederlassungen. Da insgesamt 15 Niederlassungen an der Mitarbeiterbefragung teilnahmen, nimmt uoj also 15 verschiedene Werte an. Diese 15 Werte weisen eine Varianz auf, die wir als Var(uoj) bezeichnen. Die Gesamtvarianz ergibt sich analog als Var(yij), wobei gilt, dass die Gesamtvarianz sich aus der Varianz der Niederlassungen und der Fehlervarianz addiert:
![]()
Wir wollen nun wissen, welchen Varianzanteil wir auf die Niederlassungen zurückführen können. Hier hilft uns der Intraklassen-Korrelations-Koeffizient (ICC), er relativiert den Varianzanteil der Niederlassungen an der Gesamtvarianz und kann Werte zwischen 0 und 1 annehmen:
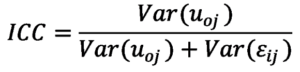
In unserem konkreten Beispiel mögen sich für die Varianzanteile (=Varianzkomponenten) die folgende Werte ergeben haben:
Var(uoj) = 86.5
Var(εij) = 62.8
Demnach berechnet sich der ICC durch:
![]()
58 Prozent der Gesamtvarianz des MI kann durch die Niederlassungen aufgeklärt werden – ein eindrucksvolles Ergebnis! Wir können also folgern, dass es zwischen den Niederlassungen gravierende Unterschiede gibt, welche die Diversität des MI erklären. Neben der rein deskriptiven Darstellung des MI für alle Niederlassungen sollten nun Variablen in weiterführende Analysen integriert werden, die auf der Niederlassungsebene gemessen werden und nicht nur auf der Mitarbeiterebene. Ein Beispiel könnten die räumlichen Bedingungen oder die Führungsqualitäten des Niederlassungsleiters sein, denn diese Variablen variieren nicht zwischen den Mitarbeitern einer Niederlassung, sondern sind für alle gleich.
Fazit – Mitarbeiterbefragung auswerten bei Unternehmen mit mehreren Standorten
Zusammenfassend können wir festhalten, dass Mehrebenenmodelle für Mitarbeiterbefragungen bei dezentralen Unternehmensstrukturen eine recht komplexe aber überaus effiziente Analysestrategie darstellen. Immerhin gilt es beim Auswerten einer Mitarbeiterbefragung eine Fülle an Informationen zu gewinnen, um anschließend Maßnahmen und Veränderungsprozesse einzuleiten. Der große Vorteil liegt vor allem darin, Maßnahmen nicht nur für das gesamte Unternehmen zu planen, sondern gezielt für jede Niederlassung Stärken und Schwächen aufzudecken und dann spezifisch zu handeln.